Stats Data Mean Media Mode Examples Funny
Statistics #01: Mean, Median, and Mode
Understanding the three most common measures of central tendency

When people need to get the "average" of something, we usually add up all the numbers/items and divide by how many numbers/items there are. This is a simple definition of mean, but there are other types of "averages" or measures of central tendencies, and each of them has its uses, depending on what you want to achieve.
In this article, we'll talk about the three most common "averages", the mean, median, and mode, and how to use them.
Mean
The mean, also represented by the Greek letter "μ", is probably the most commonly used measure of central tendency. As said before, to calculate the mean of a group of numbers, we need to add them together and divide them by how many numbers there are.
Imagine we have the list below, containing 5 numbers, and we need to find the mean of these numbers:

We can simply calculate:
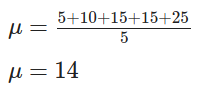
And we found that the mean is 14. Notice that the mean doesn't need to be one of the values contained in the list.
To generalize, we can say that:
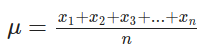
In the equation above, n represents the number of objects, or the length, of the list, and xₙ represents the nth number in the list.
Another way to write this equation is using the math summation symbol ∑, replacing x₁+x₂+x₃+…+xₙ by ∑x:
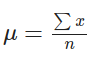
There is yet another way to represent the mean, considering the frequencies of values. Notice that in our list of five numbers (5, 10, 15, 15, 25), the number 15 appears twice.
In a small list like ours, it may not make a big difference, but when we are dealing with hundreds of recurrent numbers, it's worth considering the frequency of each number. We just need to multiply each number by its frequency, adding the results together, and then divide the result by the sum of frequencies. To illustrate, let's check out the following equation.
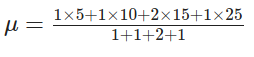
To make it simple, we can rewrite the mean equation as:
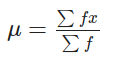
Where ∑fx is the sum of the values multiplied by their frequencies, and ∑f is the sum of the frequencies.
Median
The median is the value right in the middle of a sequence. That's probably the most direct way to describe it. But let's take a closer look, and find out when it might be a good idea to take the median into account.
Suppose there is a room with 10 recent college graduates and we're surveying the average salary of former students who just got their first jobs. The list below represents the salary of these individuals in ascending order.
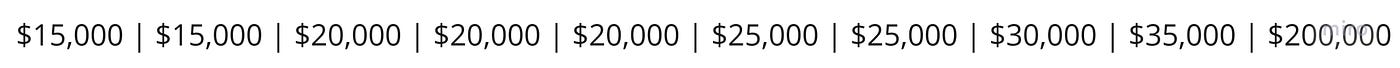
If we measure the mean of these values, we'll get $40,500 as the average graduate salary, as we can see in the histogram below.
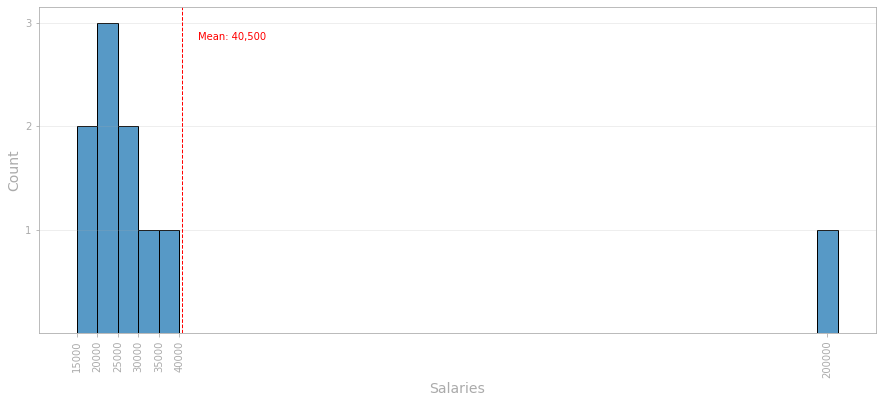
But notice that it does not represent the accurate reality, as $40,500 is considerably higher than all wages, except for one. Why is it happening? Well, one lucky person earns $200,000 a year and is distorting our evaluation.
Looking at the histogram above, it's clear that most of the values are concentrated around 20,000 to 30,000, roughly. However, there is one value that is incompatible with the others. The $200,000 salary is extreme compared to the wages of the other individuals in the room and can be called an outlier.
One of the problems with outliers is that it messes with the mean. The red dashed line in the histogram represents the mean salary in the room, $40,500, a value that is higher than 9 out of the 10 salaries in our list. The outlier is pushing the mean upwards.
In cases like this, the median might give us a better picture of the data. Remember that the median is the value right in the middle of a sequence. Here, as we have an even number of values, the median will be the mean of the two middle numbers. Let's check it out.

Observe that the median doesn't need to be one of the values contained in the list, just like the mean. However, if we had an odd set of values (let's assume we dropped the outlier and are left with 9 values), the median would be 20,000, the number right in the middle. Just remember that the numbers must be arranged in ascending order.

Let's draw the same histogram, but this time, the red dashed line represents de median of the 10 salaries.
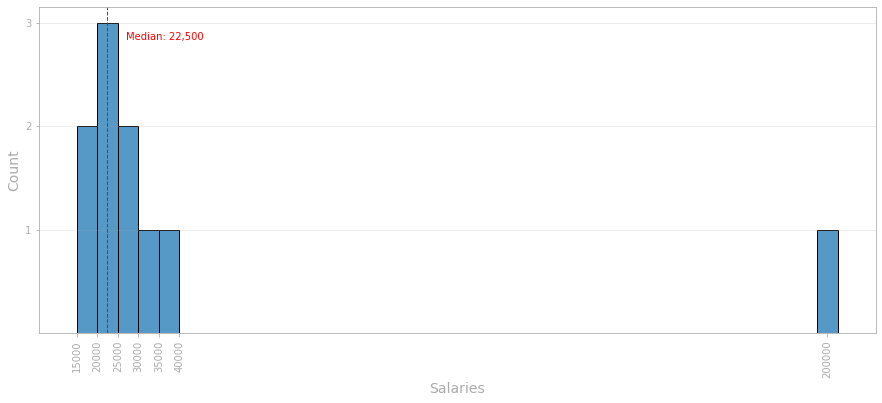
Notice that, in this case, the median describes the average salary more accurately than the mean did.
Mode
The mode can be simply described as the value (or values) that appears most frequently in a data set. Let's see how to identify the mode, and how it differs from the mean and median.
Consider the distribution below, containing 20 numbers.

Let's draw a histogram, to visualize the data set.
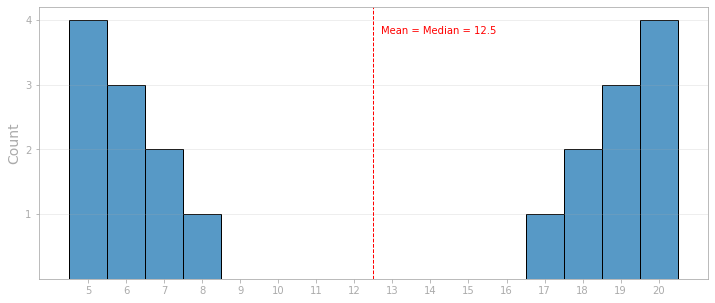
Notice that we have a cluster of values around 5 and 8 and another cluster around 17 and 20. However, both the mean and the median are 12.5, far away from those values.
The mode, unlike the mean and median, has to be one of the values contained in the set. In the case above, we have two modes, 5 and 20, because these are the most frequent values in the data set. We can say that our data is bimodal.
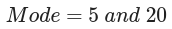
Outliers and Skewed Data
To wrap it up, let's take a brief look at some graphs that illustrate what outliers can do to our data set.
We already saw that outliers are extreme, abnormal observations in a data sample and they can distort the data. When this happens, we usually say that our data is skewed. It can be skewed to the right or the left, depending on whether the outliers are particularly high or low values.
Please take a look at the charts below.

This is a right-skewed distribution and it happens when we have the presence of abnormal high values, distorting the mean to the right. When the data is skewed to the right, the mean will be greater than the median. The salary survey above is an example of right-skewed data.
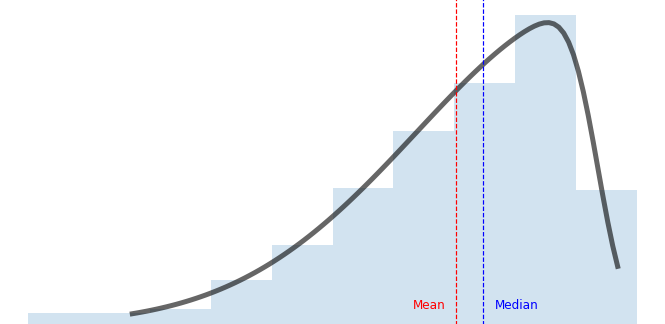
This chart above represents a left-skewed distribution. It happens when we have the presence of abnormal low values, distorting the mean to the left. When the data is skewed to the left, the mean will be lower than the median.
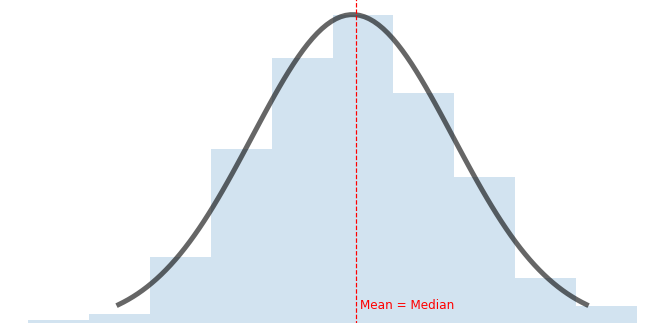
This last chart shows a symmetric distribution. When the data is symmetrical, no abnormal values are pulling the mean to the left or the right. This is a case where the mean, median, and mode have the same value.
Conclusion
Of course, much more can be said about these topics, but I hope this article may help you understand the main differences between mean, median, and mode, as well as the concept of outliers and skewed data.
To summarize, let's review what we saw here:
Mean
- Add up all the numbers and then divide by how many numbers there are.
Median
- In a set in ascending order, it's the value right in the middle.
- If the set has an even number of values, add the two middle ones together, and divide them by two.
Mode
- The most frequent value in a list.
- A data set can have several modes.
Source: https://towardsdatascience.com/statistics-01-mean-median-and-mode-d6d8597ed9f1